深度学习基础
一、模型部分
卷积神经网络的结构发展概述,主要包括:
早期探索:Hubel实验、LeNet、AlexNet、ZFNet、VGGNet 深度化:ResNet、DenseNet 模块化:GoogLeNet、Inceptionv3和Inception-ResNet、ResNeXt、Xception 注意力:SENet、scSE、CBAM 高效化:SqueezeNet、MobileNet、ShuffleNet、GhostNet 自动化:NASNet、EfficientNet
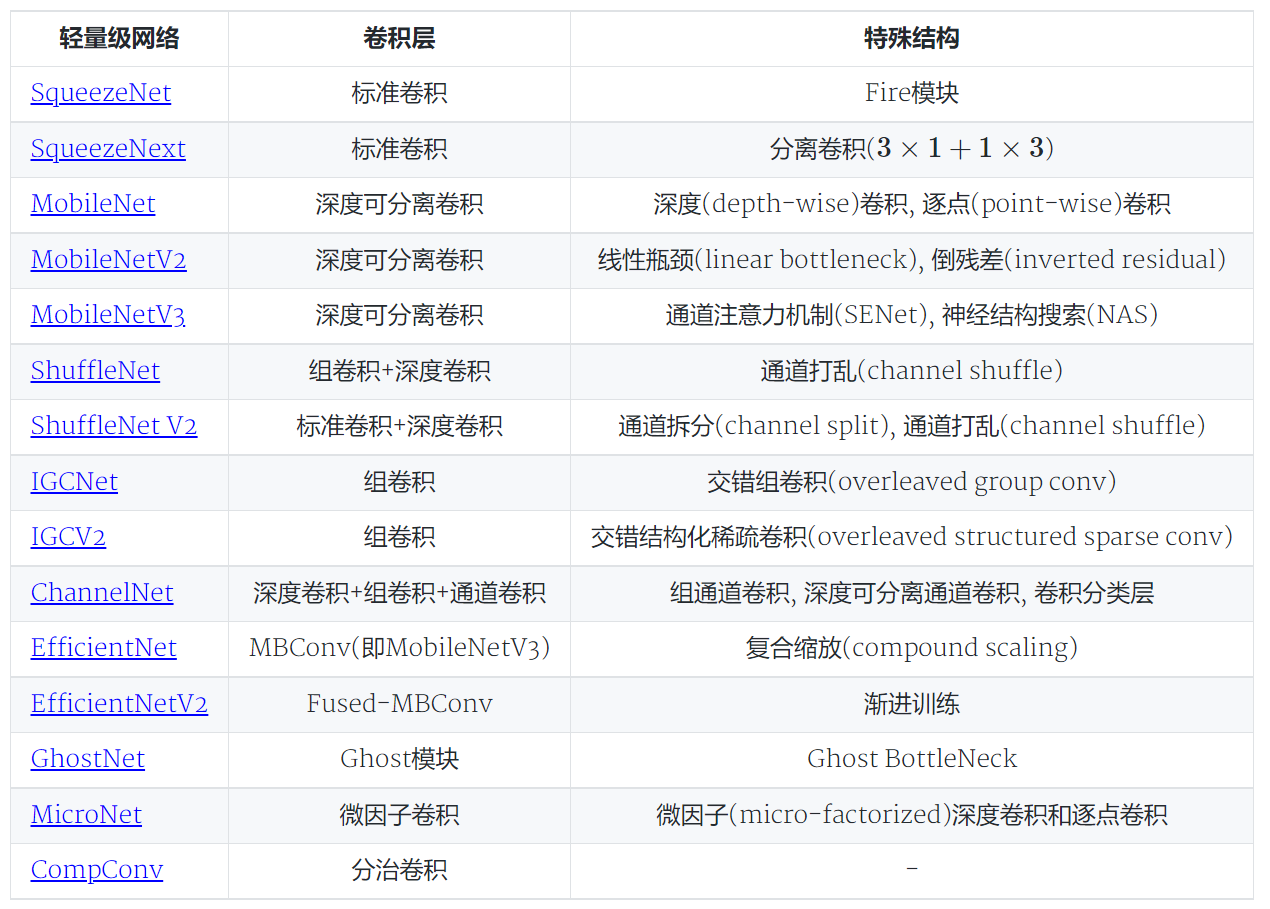
1、Resnet

由何凯明提出的ResNet通过引入残差学习使得训练深层的卷积网络成为可能。该网络设计了一种如图所示的残差连接,即在一些卷积层前后用一个恒等映射进行连接,这样主路径的卷积网络学习的是信号的残差,由于连接了这样一条恒等映射,使得在反向传播时梯度可以更容易的回传,从而减小了训练网络的困难。
总结:
1、解决网络退化的问题。(深层网络训练先降后升)
2、解决梯度消失和爆炸的问题。
2、Desnet
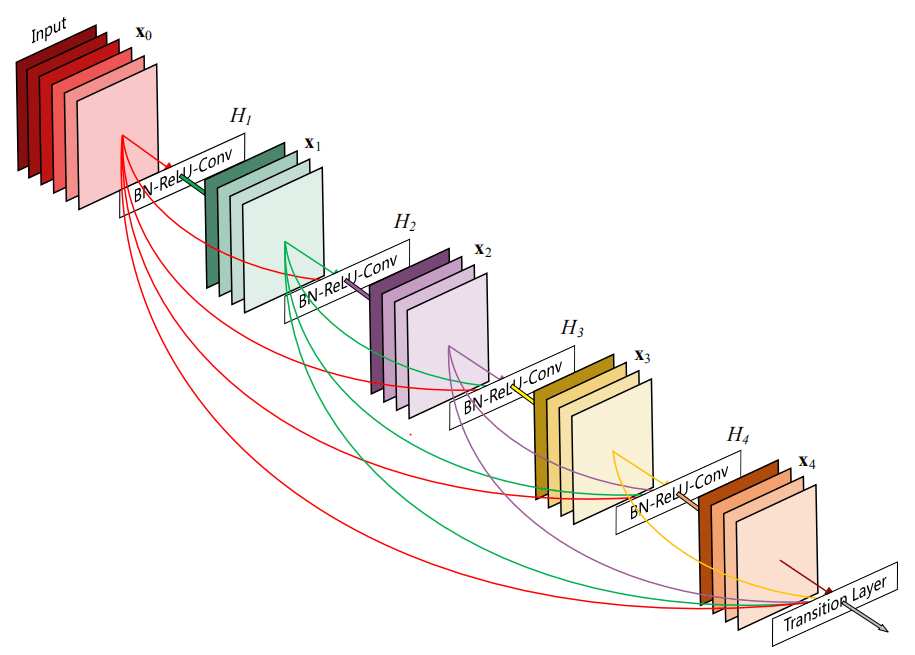
ResNet的问题在于训练了一个深层的网络,但是网络中许多层可能贡献很少或根本没有信息。为了解决此问题,DenseNet使用了跨层连接,以前馈的方式将每一层连接到更深的层中,假设网络有l层,建立了(l(l+1))/2个直接连接,并且DenseNet对先前层的特征使用了级联而不是相加,可以显式区分网络不同深度的信息。
3、MobileNet
MobileNet引入了深度可分离卷积,深度可分离卷积将传统的卷积操作分解为通道卷积和空间卷积,通道卷积是指对输入特征的每一个通道分别用一个卷积核进行逐通道地运算,而空间卷积是指使用多个1x1的卷积进行逐像素地运算,这种方法相对于传统卷积极大地减少了参数量。
4、ShuffleNet
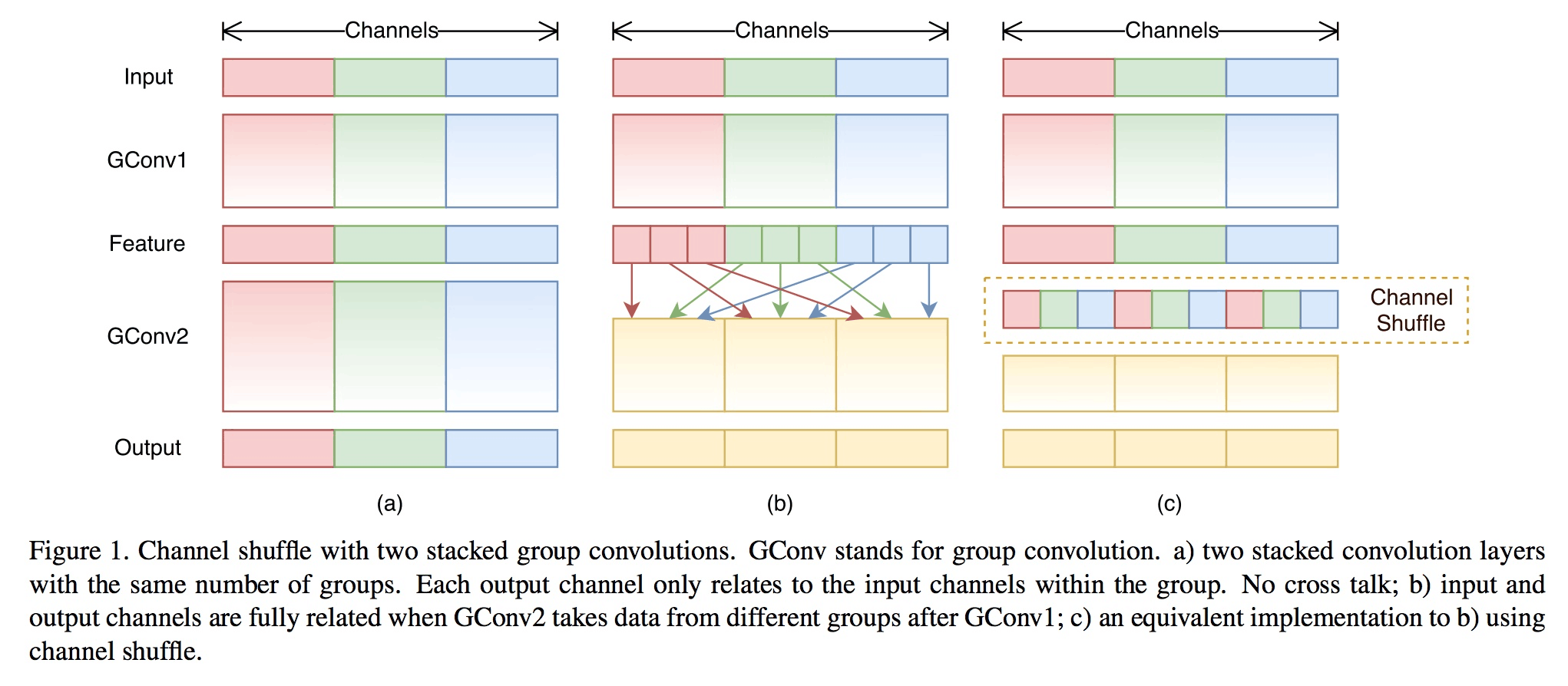
ShuffleNet引入了组卷积的概念,如图a是普通的组卷积,即将图像按特征通道进行分组,卷积操作只在每个组内进行。ShuffleNet在组卷积的同时还引入了shuffle操作。即进行一定的组卷积之后将特征的通道打乱,实现组间交互,这样压缩了模型的参数量,一定程度上保证了信息的流动。
5、SENet
SENet是最早引入注意力机制的网络之一,它在网络中引入了一条通道选择路径,该路径包括两个操作:squeeze挤压和excitation激发。挤压模块把特征映射的每一个通道挤压成一个标量,生成特征的通道统计信息;激发模块通过一个变换根据通道的统计信息重新调整每一个通道的权重,并根据权重调整原始的特征映射的每一个通道。该模块可以应用于任何卷积网络中,是一种通道的注意力机制。
6、EfficientNet
EfficientNet提出了一种兼顾速度与精度的多维度混合的模型放缩方法。它首先设计了一个基准模型,如图a所示,缩放模型的几个维度:包括网络深度(指的是网络的层数)、网络宽度(指的是网络每一层的通道数)、特征分辨率(指的是网络每一层特征的尺寸大小),通过对这三个维度固定的比例进行搜索,得到一个最佳的网络结构。
7、GhostNet
GhostNet通过实验发现,卷积得到的特征映射之间是相似的,可以用线性变换近似。网络使用较少的卷积操作获得一些特征图像,然后对这些特征图像做线性变换映射成新的特征图像,这种操作在计算上是廉价的,通过实验取得了很好的效果。
二、激活函数
S型激活函数:形如S型曲线的激活函数。包括Step,Sigmoid,HardSigmoid,Tanh,HardTanh ReLU族激活函数:形如ReLU的激活函数。包括ReLU,Softplus,ReLU6,LeakyReLU,PReLU,RReLU,ELU,GELU,CELU,SELU 自动搜索激活函数:通过自动搜索解空间得到的激活函数。包括Swish,HardSwish,Elish,HardElish,Mish 基于梯度的激活函数:通过梯度下降为每个神经元学习独立函数。包括APL,PAU,ACON,PWLU,OPAU,SAU,SMU 基于上下文的激活函数:多输入单输出函数,输入上下文信息。包括maxout,Dynamic ReLU,Dynamic Shift-Max,FReLU
三、优化方法
深度学习中的优化问题是指在已有的数据集上实现最小的训练误差l(θ)l(θ),通常用基于梯度的数值方法求解。在实际应用梯度方法时,可以根据截止到当前步tt的历史梯度信息{g1,…,gt}{g1,…,gt}计算修正的参数更新量htht(比如累积动量、累积二阶矩校正学习率等)。指定每次计算梯度所使用数据批量 BB 和学习率 γγ
基于梯度的方法存在一些缺陷,不同的改进思路如下:
- 更新过程中容易陷入局部极小值或鞍点(这些点处的梯度也为00);常见解决措施是在梯度更新中引入动量(如momentum, NAG)。
- 参数的不同维度的梯度大小不同,导致参数更新时在梯度大的方向震荡,在梯度小的方向收敛较慢;常见解决措施是为每个特征设置自适应学习率(如AdaGrad, RMSprop, AdaDelta)。这类算法的缺点是改变了梯度更新的方向,一定程度上造成精度损失。
- 在分布式训练大规模神经网络时,整体批量通常较大,训练的模型精度会剧烈降低。这是因为总训练轮数保持不变时,批量增大意味着权重更新的次数减少。常见解决措施是通过层级自适应实现每一层的梯度归一化(如LARS, LAMB, NovoGrad),从而使得更新步长依赖于参数的数值大小而不是梯度的大小。
- 上述优化算法通常会占用较多内存,比如常用的Adam算法需要存储与模型参数具有相同尺寸的动量和方差。一些减少内存占用的优化算法包括Adafactor, SM3。
- 也有一些不直接依赖于一阶梯度的方法,如零阶优化方法或使用前向梯度代替反向传播梯度。
四、正则化方法
机器学习(尤其是监督学习)的问题包括优化和泛化问题。
优化是指在已有的数据集上实现最小的训练误差(training error),泛化是指在未训练的数据集(通常假设与训练集同分布)上实现最小的泛化误差(generalize error)。深度神经网络具有很强的拟合能力,在训练数据集上错误率通常较低,但是容易过拟合(overfitting)。
正则化(Regularization)是指通过限制模型的复杂度,从而避免过拟合,提高模型的泛化能力的方法。
- Background
- L2 Regularization
- L1 Regularization
- Elastic Net Regularization
- Weight Decay
- Early Stopping
- Dropout
- DropConnect
- Data Augmentation
- Label Smoothing
五、标准化方法
输入数据的特征通常具有不同的量纲、取值范围,使得不同特征的尺度(scale)差异很大。
不同机器学习模型对数据特征尺度的敏感程度不同。如果一个机器学习算法在数据特征缩放前后不影响其学习和预测,则称该算法具有尺度不变性(scale invariance)。理论上神经网络具有尺度不变性,但是输入特征的不同尺度会增加训练的困难:
(1) 参数初始化困难
当使用具有饱和区的激活函数a=f(WX)a=f(WX)时,若特征X的尺度不同,对参数W的初始化不合适容易使激活函数陷入饱和区,产生vanishing gradient现象。
(2) 梯度下降法的效率下降
如下图所示,左图是数据特征尺度不同的损失函数等高线,右图是数据特征尺度相同的损失函数等高线。由图可以看出,前者计算得到的梯度方向并不是最优的方向,需要迭代很多次才能收敛;后者的梯度方向近似于最优方向,大大提高了训练效率。
- Background
- Normalization
- Local Response Normalization
- Batch Normalization
- Batch Renormalization
- Adaptive Batch Normalization
- L1-Norm Batch Normalization
- Generalized Batch Normalization
- Layer Normalization
- Instance Normalization
- Group Normalization
- Switchable Normalization
- Filter Response Normalization
- Weight Normalization
- Cosine Normalization
归一化(Normalization)泛指把数据特征转换为相同尺度的方法。
(1) Min-Max Normalization
最小-最大值归一化(Min-Max Normalization)将每个特征的取值范围归一到[0,1]之间:
记含有N个样本、每个样本含有P个特征的输入数据为X=(xnp)∈RN×PX=(xnp)∈RN×P,n=1,2,…,N为sample axis,p=1,2,…,P为feature axis,
^xnp=xnp−minp(xnp)maxp(xnp)−minp(xnp)x^np=xnp−minp(xnp)maxp(xnp)−minp(xnp)
(2) Standardization
标准化(Standardization)又叫Z值归一化(Z-Score Normalization),将每个特征调整为均值为0,方差为1:
记含有N个样本、每个样本含有P个特征的输入数据为X=(xnp)∈RN×PX=(xnp)∈RN×P,n=1,2,…,N为sample axis,p=1,2,…,P为feature axis,
μp=1NN∑n=1xnpμp=1N∑n=1Nxnpσ2p=1NN∑n=1(xnp−μp)2σp2=1N∑n=1N(xnp−μp)2^xnp=xnp−μpσpx^np=xnp−μpσp
(3) Whitening
白化(Whitening)在调整特征取值范围的基础上消除了不同特征之间的相关性,降低输入数据特征的冗余。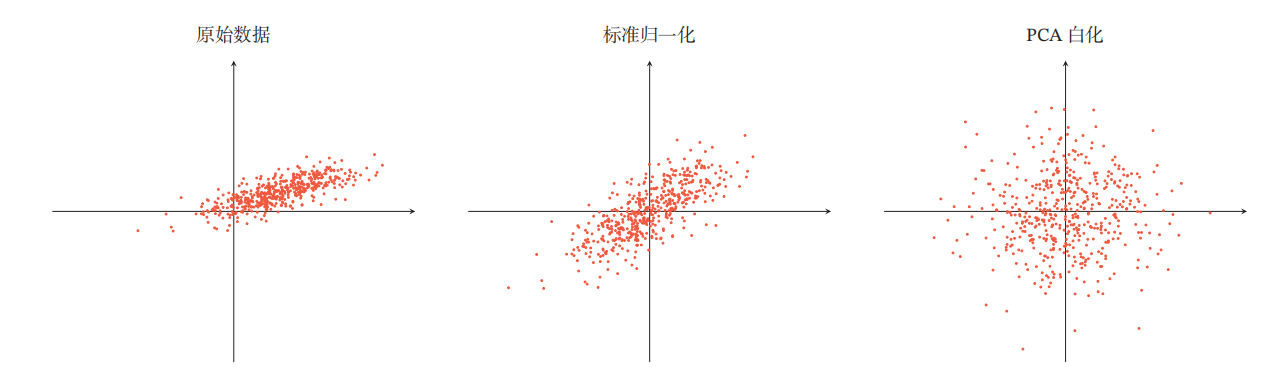 具体地,将输入数据在特征方向上被特征值相除,使数据独立同分布(i.i.d.),实现输入数据的zero mean、unit variance、decorrelated。
具体地,将输入数据在特征方向上被特征值相除,使数据独立同分布(i.i.d.),实现输入数据的zero mean、unit variance、decorrelated。
六、研究感悟
1、明确目标,小范围噪声。目标越明确,效果越好。啥效果不好,加啥样本。
2、对长的文字用长方形尺寸mobienetv3_large效果更好。
3、图片输入不是越大越好,有时候小尺寸可以使模型忽略一些细节,专注于整体。
4、整体效果出来后可以用之前的做预训练。
5、batch_size的选择:batch的size设置的不能太大也不能太小,因此实际工程中最常用的就是mini-batch,一般size设置为几十或者几百。 对于二阶优化算法,减小batch换来的收敛速度提升远不如引入大量噪声导致的性能下降,因此在使用二阶优化算法时,往往要采用大batch哦。此时往往batch设置成几千甚至一两万才能发挥出最佳性能。 GPU对2的幂次的batch可以发挥更佳的性能,因此设置成16、32、64、128…时往往要比设置为整10、整100的倍数时表现更优。
6、我通过对浅层宽模型设置2-3倍默认的Weight Decay往往效果是最好的。太大了实际会严重干扰第一个Learning Rate阶段的精度。太小了(也就是很多论文的默认设置)会距离收敛最优情形有差距。CIFAR100 Top-1 84.36%是在Weight Decay=0.001上获得的。也就是说,在实践里我比其他人更喜欢加大Weight Decay。
7、常用训练方法
batch size 1024
epoch 150
learning rate 0.4 (ramps up from 0.1 to 0.4 in the first 5 epochs)
LR decay strategy cosine
weight decay 0.00004
dropout rate 0.2 (0.1 for Small-version 0.75)
no weight decay biases and BN
label smoothing 0.1 (only for Large-version)
七、行业术语
-
feature:一个数组
-
representation:还是一个数组
-
embedding:把输入映射成数组
-
提高泛化性:预测更准了
-
过拟合:训练过头了
-
attention:加权
-
adaptive:还是加权
-
few-shot learning:看了几个样本就学
-
zero-shot learning:一个没看就开始瞎蒙
-
self-supervised:自学
-
semi-supervised:教一点自学一点
-
unsupervised:没人教了,跟谁学?
-
end-to-end:一套操作,行云流水搞到底
-
multi-stage:发现不行,还得一步一步来
-
domain:我圈起来一堆样本,就管他叫一个domain
-
transfer:我非得在这一堆样本上训练,用在另一堆样本上,就是不直接训练,就是玩~
-
adversarial:我加了一部分就是让loss增大
-
robust:很稳我不会让loss变大的(但也不容易变小了)…………
-
state of the art(sota):我(吹nb)第一
-
outperform:我虽然没第一,但是我比baseline强
-
baseline:(故意)选出来的方法,让我能够outperform
-
empirically:我做实验了,不知道为啥
-
worktheoretically:我以为我知道为啥work,但没做实验,或者只做了个toy model……………
-
multi开头词组multi-task:把几个loss加一起,完事
-
multi-domain:把几堆儿样本混一块训练,完事
-
multi-modality:把视频语音文字图像graph点云xxx混一块训练,完事